
App development as a topic covers the sequence of stages, common organizational methods, and the software tools that teams use to produce mobile and web applications. The lifecycle typically describes phases such as requirements gathering, design, implementation, testing, deployment, and ongoing maintenance. Methodologies address how work is organized and iterated — for example, approaches that emphasize fixed phases versus iterative cycles. Common tools include version control systems, issue trackers, interface design applications, build automation, and runtime frameworks that support development and delivery. Discussing these elements together helps clarify how projects move from concept to a maintained product.
Within the lifecycle, interactions among phases are often bi-directional: testing may reveal design changes, and operations feedback can influence requirements. Methodologies define the cadence of those interactions — teams using iterative approaches may plan in short cycles and reassess priorities frequently, while teams using sequential approaches may complete full design specifications before development. Tooling supports both coordination and technical execution: code repositories preserve history, task boards track progress, design tools prototype interfaces, and CI/CD systems can automate builds and tests. These components together shape how predictable, traceable, and repeatable a project can be.
Methodologies such as Agile and Kanban typically influence planning granularity, communication frequency, and the artefacts produced. For instance, teams practicing Scrum often structure work into regular sprint cycles with defined planning and review events that may produce incrementally shippable features. Kanban may emphasize limiting work-in-progress and visualizing flow on a board. These methodologies can be combined with DevOps practices so that iterative deliverables are validated through automated builds and tests. The choice of methodology often depends on project scale, stakeholder preference, and the need for frequent feedback.
DevOps and CI/CD practices often focus on automating repetitive technical steps to reduce manual errors and accelerate feedback. A typical CI/CD pipeline may include code compilation, unit testing, static analysis, integration testing, and automated deployment to staging environments. Automation tools may integrate with version control to run these steps on each change, which can surface integration issues earlier. Continuous delivery approaches may be paired with feature-flagging mechanisms so teams can control exposure of new functionality without full releases, allowing incremental validation in production-like conditions.
Tool choice affects team collaboration and technical constraints. Version control systems such as Git provide branching and history tracking, which may support parallel workstreams. Issue trackers and project boards can represent requirements and tasks at varying levels of detail, helping coordinate developers, designers, and testers. Design and prototyping tools allow quick validation of interfaces before heavy engineering effort. UI frameworks and cross-platform toolkits may influence performance profiles and developer productivity, and teams often evaluate trade-offs between native performance and reuse across platforms.
Quality assurance spans multiple levels: unit tests validate small pieces of code, integration tests verify module interactions, and end-to-end tests exercise complete flows. Testing strategies may blend automated suites and manual exploratory testing; automated tests can run frequently in CI while manual testing may focus on usability and edge cases that are hard to script. Measurement and observability complement testing by providing runtime signals from staging and production environments, enabling teams to detect regressions or performance degradations and feed that information back into planning and maintenance phases.
In summary, understanding app development requires attention to the lifecycle phases, the methodologies that structure work, and the tooling that enables execution. Each of these elements may interact: methodologies shape workflows, tools enable automation and collaboration, and lifecycle stages guide when to apply particular practices. Project context, team composition, and risk tolerance typically influence combinations of approaches and technologies. The next sections examine practical components and considerations in more detail.

Planning and design form the initial parts of the app lifecycle and are influenced by chosen methodologies. In iterative methods, planning may break work into short cycles with a prioritized backlog of features, whereas sequential approaches may produce comprehensive requirement documents before coding begins. Design work often includes user research, information architecture, wireframes, and high-fidelity prototypes. Tools for design and prototyping may help validate flows with stakeholders and collect feedback; teams commonly keep design assets linked to issue trackers so design decisions are visible across the project.
Requirements and scope management practices differ by methodology and risk tolerance. Agile approaches may treat requirements as evolving artefacts that can change as the team learns, while linear approaches may lock scope earlier to reduce change. Planning artifacts — user stories, acceptance criteria, and mockups — provide testable expectations for development. Teams may also produce non-functional requirements covering performance, security, and accessibility, which can be important inputs to architectural decisions and tool selection.
Design systems and component libraries may reduce duplication and increase consistency across an application. Using shared component inventories can accelerate development and make design-to-code handoffs smoother, particularly in multi-platform projects. Cross-functional reviews, such as design critiques or architecture review boards, may be scheduled during planning phases to align on usability and technical constraints. These practices typically help teams maintain coherent user experiences without prescribing a single method for all projects.
Planning and design often include risk assessment and estimation activities that may shape delivery expectations. Estimation techniques such as story points or time-based estimates can help teams forecast capacity and prioritize work, while risk logs may track technical uncertainty or external dependencies. Understanding likely integration points, third-party services, or regulatory constraints early can influence architecture, testing needs, and the selection of tooling for later stages of the lifecycle. Continued review of planning outputs may reduce surprises during implementation.

Development and implementation are the stages where code is produced and integrated. Methodologies affect how work is organized: in iterative cycles, small increments of functionality are implemented and integrated frequently, which may encourage short feedback loops. Teams commonly employ version control systems like Git to manage source code and branching strategies; branching models can range from trunk-based practices to feature-branch workflows, each with different implications for integration frequency and merge complexity.
Programming languages and frameworks are selected based on platform targets, performance needs, and team expertise. For web applications, frameworks such as React or Angular may be used to structure UI, while mobile development may use native SDKs or cross-platform toolkits like Flutter that allow a single codebase for multiple platforms. Frameworks often come with ecosystem tools for testing, state management, and build processes; teams typically evaluate trade-offs around runtime performance, developer velocity, and long-term maintainability when selecting a stack.
Code quality practices commonly include code reviews, static analysis, and automated unit tests that integrate into CI pipelines. Peer reviews may improve maintainability and knowledge sharing, while static analysis tools can catch common issues early. CI systems can run these checks on every commit, enabling teams to detect regressions promptly. Adoption of such practices may vary by team size and project risk level, but they generally support more predictable integration and delivery when combined with consistent branching and deployment approaches.
Integration points such as APIs, databases, and third-party services often define technical boundaries that require coordination and agreement. Clear API contracts, versioning strategies, and mock services for local development can reduce friction between teams and components. Teams may also consider backward compatibility and data migration processes during implementation to avoid runtime failures when a new release is deployed. Proper documentation of interfaces and configuration reduces integration effort across the lifecycle.
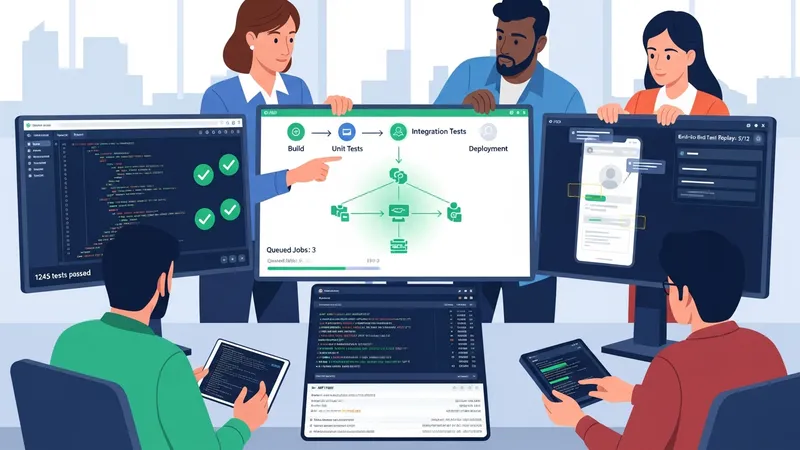
Testing and quality assurance span multiple activities that validate functionality, performance, and reliability. Methodologies influence when these activities occur: iterative development often integrates automated test suites into CI so tests run on each change, while some sequential approaches may emphasize larger test phases after development completion. Test types typically include unit tests for small code units, integration tests for component interactions, and end-to-end tests that simulate user flows. Teams commonly balance automated and manual testing based on the stability and complexity of features.
Test automation frameworks and tooling can vary by platform and language. Unit testing frameworks, UI automation tools, and API testing tools may be combined within CI pipelines to provide layered coverage. Performance testing tools may be introduced where load characteristics are important, and observability tools may capture runtime metrics during staging or canary deployments. Choosing suites that integrate smoothly with CI/CD systems often reduces overhead in test execution and reporting, which may lead to faster feedback on code quality.
Test data management and environment provisioning are practical considerations that affect test reliability. Creating reproducible test environments using containerization or infrastructure-as-code can reduce environmental flakiness and support parallel test runs. Managing realistic test data while respecting privacy rules may require anonymization techniques or synthetic data generation. Teams may also use feature toggles and staged rollouts to limit user exposure to changes while validating behavior under real-world conditions.
Quality metrics such as test coverage, defect rates, and mean time to recovery (MTTR) can provide insights but should be interpreted cautiously. Metrics may indicate trends that prompt investigation rather than serve as absolute success criteria. Cross-functional involvement in testing, including developers, QA engineers, and product stakeholders, often helps identify gaps in coverage and align expectations about acceptable risk. Regular retrospectives can surface process improvements that affect testing effectiveness over time.

Deployment and ongoing maintenance conclude the primary lifecycle loop and are supported by tooling that addresses release automation, monitoring, and configuration management. DevOps practices typically emphasize automated deployments and infrastructure as code so environments can be reproduced and changes tracked. Continuous deployment approaches may push changes frequently to production-like environments, while controlled release strategies such as canary releases or blue-green deployments may be used to reduce exposure when risk is higher.
Operational observability includes logging, metrics, and tracing, which together provide runtime visibility into application health and user experience. These signals often feed back into backlog items for bug fixes or performance tuning. Incident management practices and post-incident reviews can reduce recurrence of failures and inform future design decisions. Maintenance tasks such as dependency updates, security patches, and performance optimizations are ongoing responsibilities that may be scheduled into regular cycles or handled as part of continuous work.
Tooling choices for deployment and maintenance often include container orchestration platforms, configuration management tools, and cloud service providers. Teams may evaluate trade-offs between managed services that reduce operational burden and self-managed infrastructure that offers more control. Backup and recovery strategies, access controls, and audit logging are operational considerations that can affect compliance and risk profiles. The selection of automation and monitoring tools may be guided by team skill sets, cost considerations, and integration capabilities with existing pipelines.
Maintenance and evolution of an application typically require intentional planning for technical debt, modularity, and documentation. Code refactoring, retired features, and upgrade paths for dependencies may be scheduled to avoid long-term degradation. Documentation that includes architecture diagrams, runbooks, and interface contracts often supports faster incident resolution and onboarding of new contributors. Over time, measuring user behavior and operational metrics can inform prioritization of maintenance versus new feature work, helping teams align investments with product goals and stability needs.