
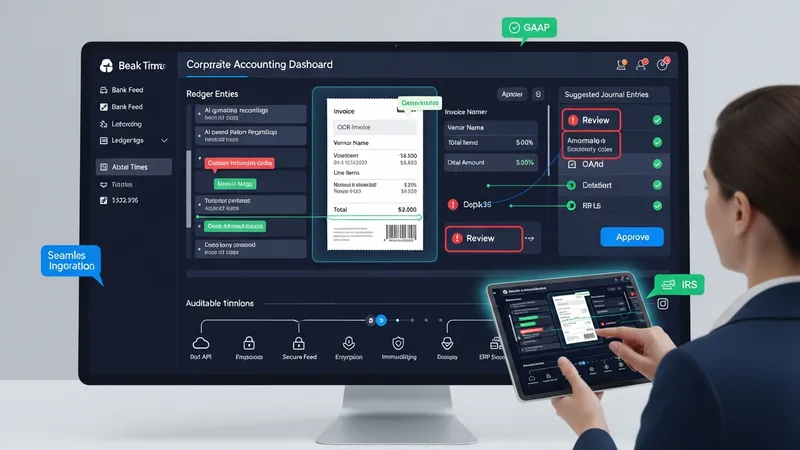
Intelligent software agents for finance automate routine accounting tasks by applying machine learning, natural language processing, and business rules to financial data. These systems ingest bank feeds, invoices, receipts, and ledger entries to perform tasks such as transaction categorization, invoice extraction, and preliminary reconciliations. Within an accounting environment, they may generate suggested journal entries, flag anomalies for review, and create structured workflows that route items to human reviewers when confidence is low. The tools typically operate alongside existing ledgers and enterprise resource planning (ERP) systems to reduce repetitive manual work and to produce auditable trails of automated actions.
Architecturally, these agents often combine optical character recognition (OCR) for document capture, pattern recognition for mapping transactions to chart-of-accounts codes, and rule-based layers that enforce firm policies. Many deployments keep a human-in-the-loop for approvals and corrections so that models learn from verified outcomes. In the United States context, implementations commonly consider IRS recordkeeping rules and Generally Accepted Accounting Principles (GAAP) when structuring retention and classification. Security measures such as encryption and access controls are typically applied, and integrations are commonly performed through APIs or secure bank feeds.
Comparing these examples shows differences in scale and focus: QuickBooks Online is typically positioned for small to mid-sized firms with embedded AI helpers for day-to-day bookkeeping; Bill.com focuses on AP/AR automation and workflow orchestration; BlackLine targets enterprise reconciliation and close processes. Selection and fit often depend on the size of the finance function, the complexity of accounting policies under U.S. GAAP, and existing system footprints. Organizations commonly evaluate integration effort, expected automation coverage, and the need for human review when assessing which approach aligns with their operations.
Data governance and auditability are frequent focal points during deployments. In the United States, finance teams often map automated classification outputs to established chart-of-accounts structures and maintain logs that support IRS compliance and audit trails. Models may be tuned to respect entity-level policies, cost-center allocations, and internal control frameworks. Where confidence thresholds are low, items are routed to an accountant for verification; where confidence is high, agents may post draft entries for batch review. This layered approach typically reduces manual cycles while preserving oversight.
Accuracy measurement and continuous improvement are operational considerations. Teams often track match rates for automated bank reconciliation, OCR extraction accuracy for invoices, and the percentage of transactions requiring manual recoding. Those metrics may be used to retrain models or refine rule sets. Integration testing with U.S. banking feeds, payroll systems, and tax reporting workflows is commonly scheduled before full production use. Vendors and internal teams often document rollback procedures and data backups to manage model errors and maintain financial statement integrity.
Cost and implementation complexity can vary substantially across the range of intelligent agents. Small businesses may deploy cloud tools within weeks, while enterprise reconciliations or ERP-integrated solutions often require months of configuration, testing, and change management. Typical cost drivers include user counts, volume of transactions, required connectors (bank, payroll, ERP), and the level of customization for internal controls. Contract terms often specify support levels and data handling responsibilities relevant to U.S. regulatory expectations.
In summary, intelligent finance agents automate classification, document capture, and reconciliation tasks by combining machine learning, rules, and human oversight in accounting workflows. Implementations in the United States typically consider GAAP alignment, IRS retention requirements, and system integration needs. Performance metrics, governance controls, and phased rollout approaches are commonly applied to manage risk and accuracy. The next sections examine practical components and considerations in more detail.
There are several functional types of intelligent agents deployed within U.S. accounting environments. Transaction classification agents analyze bank feeds and map entries to chart-of-accounts codes, often using historical labeling to suggest categories. Invoice capture agents apply OCR and NLP to extract vendor, date, line items, and amounts from submitted invoices and receipts. Reconciliation engines compare ledger balances to external statements to identify mismatches and suggest adjustments. Cash-flow assistance or forecasting agents use historical inflows and outflows to generate short-term liquidity projections that finance teams may use for planning.
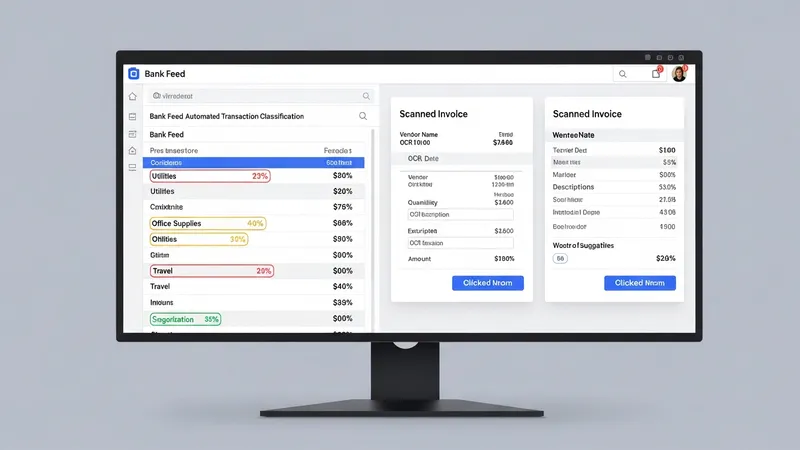
Each type typically integrates with existing systems: small businesses often connect transaction classifiers to QuickBooks Online or similar ledgers, while larger enterprises link reconciliation engines to ERP systems and subledger modules. In the U.S., teams may verify that extracted invoice fields satisfy IRS documentation requirements and that allocations comply with GAAP. Where models produce uncertain suggestions, many implementations route items to human reviewers to confirm or correct outputs, helping preserve the audit trail.
Performance expectations differ by type. OCR-based invoice extraction may frequently require template tuning for diverse vendor formats, while transaction classifiers often improve quickly with consistent vendor patterns and recurring transactions. Reconciliation engines can automate low-complexity accounts first (e.g., cash and bank), then extend to more complex subledgers. Consideration of internal control frameworks and potential SOX requirements for public companies is often part of the design phase in U.S. enterprise deployments.
Operational considerations include monitoring model drift, logging decisions for auditability, and maintaining mappings between automated outputs and the organization’s chart of accounts. Teams commonly plan phased rollouts: piloting one agent type, evaluating metrics such as match rate and manual override frequency, and scaling once governance and accuracy criteria are met. These steps are described to inform planning rather than to prescribe a single approach.
Integration patterns usually rely on APIs, secure file transfers, and bank connectivity services. Agents ingest data from bank feeds, payment platforms, ERP records, and invoice directories. In the United States, common ledger targets include QuickBooks Online and enterprise ERPs; third-party connectors such as Plaid or direct bank APIs are often used to bring transaction data into the processing pipeline. Proper mapping of vendor IDs, accounts, and tax codes is commonly performed during setup to ensure that automated outputs align with existing financial structures.

Data flow design must address latency, error handling, and reconciliation between source systems. Typical deployments batch-process incoming documents overnight or process items in near real time depending on business needs. Error-handling patterns include quarantining unrecognized invoices, flagging mismatches for manual review, and maintaining versioned records of automated suggestions. U.S. organizations frequently validate that data retention and access controls meet IRS document retention expectations and any sector-specific compliance rules.
Security and data residency are practical integration considerations. Many vendors host services within U.S. data centers or provide contractual assurances about where data is stored; these choices are often reviewed in light of corporate policies and regulatory requirements. Encryption in transit and at rest, role-based access controls, and logging of administrative actions are standard features that finance and IT teams inspect during procurement and integration testing phases.
Insider considerations include mapping automation outputs to existing reconciliation schedules and audit workflows, synchronizing posting windows to month-end close calendars, and planning for fallback procedures if connectors fail. Teams may also set up dashboards to monitor throughput, exceptions, and human override rates to inform tuning and governance decisions over time. These items are presented as typical considerations rather than endorsements of any specific technical approach.
Accuracy measurement commonly uses metrics such as correct-category rate for transaction classification, field-extraction accuracy for invoices, and match rates for reconciliation. Organizations often set conservative confidence thresholds so that only high-confidence suggestions are auto-posted, while lower-confidence items are routed for human review. In the United States, public companies may evaluate how automation interacts with Sarbanes-Oxley (SOX) controls, and all entities typically consider audit trails that document who approved or changed automated outputs.

Internal controls around automated processes are usually layered: preventive controls constrain model outputs to valid account ranges, detective controls alert users to anomalies, and corrective controls document how exceptions are resolved. Vendors and internal teams often record detailed logs of automated decisions and human overrides to support auditors and inquiries from regulators such as the IRS or the Securities and Exchange Commission (SEC) where applicable. These records are typically designed to support GAAP-compliant financial reporting.
Model explainability and transparency are practical areas of focus. Finance teams may require that the system provide rationale or supporting evidence for suggested categorizations and value extractions—such as matching vendor names or prior transaction history—so reviewers can assess why a decision was made. Regular audits of model performance and periodic retraining using confirmed outcomes are commonly used to limit drift and to show that controls are operating effectively over time.
Compliance also involves retention and retrieval policies. In the U.S., standard practice is to retain records in line with IRS guidelines and to ensure that automated records are searchable for audit purposes. Contractual terms with vendors often specify responsibilities for data retention and the ability to export data if a relationship changes. These points are typical planning topics for teams considering automation and are offered as informational considerations.
Pricing models for intelligent finance agents commonly include subscription fees, per-user licensing, per-transaction fees, or enterprise agreements with multi-year commitments. For small-business tools, monthly subscriptions in the range noted earlier for QuickBooks Online or Bill.com are typical, while enterprise reconciliation platforms often involve annual contracts amounting to several thousand dollars. Implementation and professional services costs are additional drivers, particularly for ERP integrations and custom mappings.

Deployment timelines often vary with scope: a pilot for invoice capture or transaction categorization may take a few weeks, whereas full ERP-integrated reconciliations and close automation can extend to several months. Resource planning typically includes vendor configuration, internal process mapping, staff training, and change management. Many U.S. organizations budget for ongoing monitoring and periodic model maintenance as part of total cost of ownership.
Operational staffing considerations include the need for a small team to manage exceptions, monitor metrics, and approve uncertain items. Finance teams often adjust roles so that accountants focus more on analysis and exception handling rather than repetitive data entry. IT involvement is commonly required for secure integrations, identity management, and backup strategies. These shifts are described as typical patterns rather than prescriptive staffing models.
When evaluating costs and models, U.S. organizations often consider vendor support levels, data residency, and contractual terms relating to liability and data handling. Benchmarks such as manual hours saved, reduction in exception counts, and improvements in close-cycle timing are commonly tracked to inform continued investment. These considerations are intended to inform planning and comparison rather than to recommend a particular vendor or pricing strategy.