
Cloud hosting refers to delivering computing resources from remote infrastructure owned or operated by third parties, while managed IT services describe ongoing technical support and operational tasks performed by external teams. Together, these approaches separate hardware ownership from application delivery and shift routine system administration—such as patching, backups, capacity scaling, and network configuration—onto remote platforms or service teams. Organizations may use virtual machines, containers, object and block storage, and network services provided by cloud platforms alongside managed services that coordinate monitoring, incident response, and routine maintenance.
In practice, the combination of remote infrastructure and managed operations creates distinct roles: platform providers supply compute, storage, and networking primitives; managed teams handle configuration, observability, and user-facing service continuity. This separation can allow organizations to focus internal staff on domain-specific development or data tasks while relying on external tools and processes for infrastructure lifecycle activities. Typical managed arrangements include scheduled maintenance, security patching, backup verification, and service-level reporting, each aligned to contractual scopes of work and technical interfaces.

Comparing these examples, IaaS provides foundational resources that may be self-managed or paired with managed operations, whereas platform tools like Kubernetes introduce a layer of abstraction for application deployment and scaling. Managed operations methods typically focus on recurring tasks: log aggregation, patch scheduling, and automated backups. Each approach may influence staffing models, tooling choices, and integration effort; for instance, using a container platform often requires observability integrations and runbook documentation to support managed responders.
Architectural frameworks often used with cloud hosting and managed services include layered responsibility matrices that assign tasks between the infrastructure provider, managed team, and in-house stakeholders. These matrices may clarify who is accountable for network rules, OS patching, data retention, and application configuration. Clear boundaries can reduce overlap and enable predictable incident handling, but they typically require ongoing governance to adapt as deployments or compliance needs change.
Operational maturity in this space can hinge on automation and repeatable processes. Infrastructure-as-code, continuous integration and delivery, and configuration management often form the technical foundation for both cloud-hosted systems and managed support. Using standardized templates and version-controlled configuration may reduce manual drift and enable quicker recovery, while allowing managed teams to execute consistent maintenance across environments with fewer ad-hoc interventions.
Use cases for combining cloud hosting and managed IT services commonly include web applications, analytics platforms, and disaster recovery setups. Web applications may leverage auto-scaling and managed load balancing, analytics deployments often rely on scalable storage and managed ingestion pipelines, and disaster recovery configurations typically pair replicated storage with tested failover procedures. Each use case can impose different priorities—latency, throughput, or recovery time—which influence the choice of hosting constructs and managed service scopes.
In summary, cloud-hosted infrastructure paired with ongoing managed operations forms a collaborative model where platform primitives and operational expertise combine to deliver and sustain digital services. This model may help organizations allocate internal resources differently, introduce standardization through orchestration and automation, and clarify responsibilities across providers and teams. The next sections examine practical components and considerations in more detail.
Core infrastructure components typically include compute instances, container runtimes, block and object storage, virtual networking, and identity and access controls. Compute can range from provisioned virtual machines to serverless functions and containers; each model may affect operational visibility and cost characteristics. Storage choices often balance performance, durability, and access patterns—for example, high-throughput block storage for databases versus object storage for archival data. Identity controls and network segmentation are central to isolating workloads and managing permissions between managed teams and internal users.
Resource allocation models commonly used are reserved or on-demand provisioning and autoscaling groups that adjust capacity to demand. Autoscaling may reduce manual intervention but typically requires reliable metrics and health checks to avoid unintended scaling. Reservations or savings plans can be used where predictable workloads exist to control baseline costs. Managed teams often establish policies for provisioning and lifecycle management to enforce tagging, cost allocation, and retirement procedures so resources do not remain unmanaged.
Integration of platform tools such as container orchestrators often changes the operational footprint. Orchestration introduces control planes and stateful storage considerations that must be addressed by both platform engineers and managed operators. For stateful workloads, managed services typically include procedures for backup, snapshot lifecycle, and restoration validation. Stateless application components can often be redeployed more easily, but they still require monitoring and configuration management to maintain consistency across deployments.
When designing infrastructure for combined cloud hosting and managed services, teams often consider service-level objectives and recovery expectations alongside technical constraints. Defining measurable metrics—availability percentages, mean time to recovery ranges, and backup frequency—helps align managed tasks with business needs. Such definitions may be revisited periodically as application usage patterns evolve or when dependencies change, supporting more effective coordination between infrastructure components and managed operational responsibilities.
Monitoring and observability typically form the backbone of operational management, combining metrics, logs, and traces to provide situational awareness. Managed teams often implement centralized log aggregation and dashboards to correlate alerts and incidents. Health checks, synthetic transactions, and resource metrics such as CPU, memory, and I/O utilization are commonly used to detect anomalies. Effective monitoring setups usually include escalation policies and documented incident response procedures to route issues to the appropriate operators or engineers.

Incident management workflows for cloud-hosted systems generally include detection, triage, mitigation, and post-incident review. Managed responders may handle the initial triage and mitigation steps and then coordinate with in-house teams for deeper investigation or code changes. Runbooks and playbooks—documented step sequences for common failures—can reduce response time and ensure consistent handling. Over time, analyses of incidents often inform automation of repetitive remediation tasks.
Capacity planning and performance tuning are ongoing activities that can be supported by managed services. Historical utilization trends typically inform scaling policies and resource adjustments. Performance tuning may involve database indexing, caching strategies, or adjusting compute allocations. Managed teams often provide recurring reviews of performance trends and suggest configuration changes, although final implementation may involve cross-functional coordination with developers and architects.
Change management is an operational consideration that commonly affects stability in cloud environments. Scheduled maintenance windows, staged deployments, and canary releases may be used to limit exposure when applying updates. Managed service arrangements frequently include change approval and communication processes to ensure stakeholders are informed and rollback paths are defined. These practices may reduce the likelihood of disruptive changes while enabling iterative updates.
Security controls for cloud-hosted systems often blend provider-native features with supplemental tooling managed by service teams. Access management, network segmentation, encryption at rest and in transit, and vulnerability scanning are common elements. Managed service providers may operate these controls under agreed scopes—running scans, applying patches, and monitoring for suspicious activity—while customers retain responsibility for application-level security and sensitive configuration details, depending on the chosen shared-responsibility model.
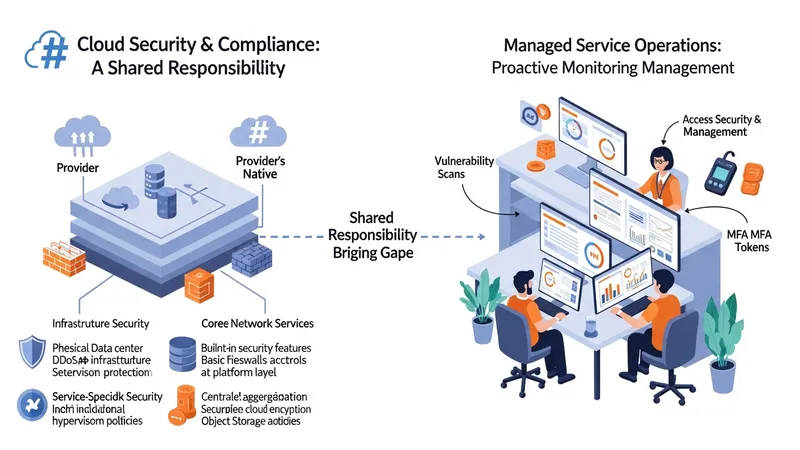
Compliance considerations frequently depend on industry requirements and data classification. Managed arrangements typically outline responsibilities for retention policies, audit logging, and evidence collection. Organizations may map regulatory obligations to technical controls—retention schedules to object lifecycle rules, or audit trails to immutable logging systems. Managed teams often support evidence gathering for audits by preserving logs and snapshots, but documented responsibilities should define which party provides specific artifacts and attestation.
Data protection strategies commonly include regular backups, replication, and tested recovery procedures. Backup cadence may be aligned to recovery point objectives and retention requirements; managed teams often perform regular verification of backup integrity and restoration drills. Encryption management—key rotation and secure key storage—may be a shared concern; teams may use provider key management or external systems depending on their trust and compliance posture.
Threat detection and response can leverage a mixture of native alerts, security information and event management, and managed security operations. Managed services may provide alert triage and initial containment steps, while escalation paths route more complex investigations to specialized security teams. Continuous improvement through periodic vulnerability assessments and patch management cycles typically forms part of a layered defense strategy, stated and executed as organizational considerations rather than guaranteed prevention.
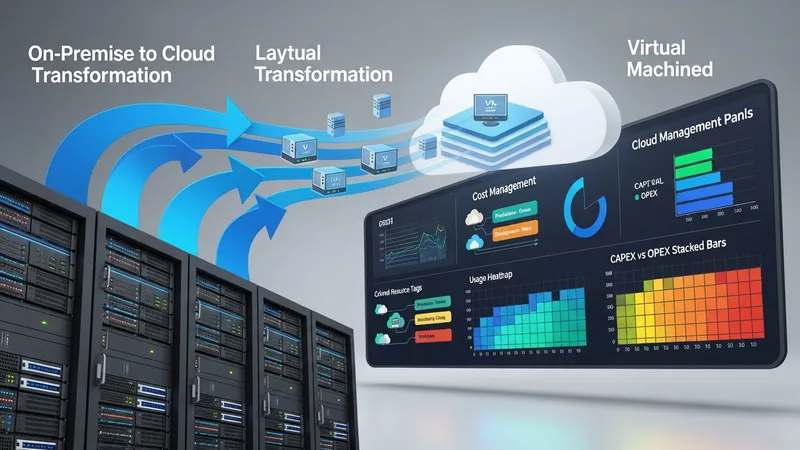
Cost management in cloud environments often involves monitoring usage, applying tagging for allocation, and selecting appropriate resource classes for workloads. Organizations may find that moving a workload to cloud hosting changes cost profiles—reducing capital expenditures but introducing variable operational costs. Managed services add recurring operational fees that should be considered alongside infrastructure consumption; budgeting typically includes both resource usage and the scope of managed tasks such as backup retention or 24/7 monitoring.
Performance considerations depend on workload characteristics: latency-sensitive applications may prioritize colocated resources or edge services, while batch-processing systems may favor throughput and parallelism. Benchmarking and load testing are common practices used to characterize performance under expected load. Managed teams often assist by running periodic performance assessments and recommending configuration adjustments, framed as technical considerations to balance cost and expected service behavior.
Migration strategies to cloud-hosted platforms may include rehost, replatform, or refactor approaches. Each strategy has trade-offs: rehosting can be quicker but may not leverage cloud-native efficiencies; refactoring can improve scalability but requires more engineering effort. Managed providers can support migration activities through planning, execution, and validation services; typical engagements include phased migrations, replication testing, and post-migration tuning to align performance and operational practices with new hosting constructs.
Ongoing optimization commonly combines cost reviews, right-sizing of resources, and lifecycle management for services. Organizations may schedule periodic reviews to assess idle resources, identify overprovisioned instances, and refine scaling policies. Such optimization is an iterative process where managed services and internal teams collaborate to adjust configurations, update automation, and document changes, presented as considerations to guide sustainable hosting and operations rather than as prescriptive rules.